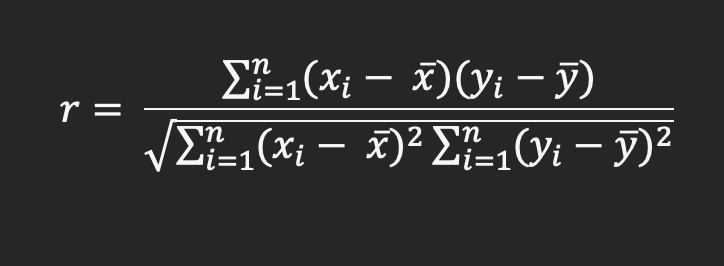
A pair of random variables can have three kinds of relationships: correlated, uncorrelated, or independent.
Linear correlation, often referred as correlation, is a statistical measure that captures the degree of a linear relationship between two random variables. The correlation coefficient, computed between a pair of random variables, determines whether the variables are correlated or uncorrelated.
Correlation coefficient values range from -1 to +1, providing two key insights:
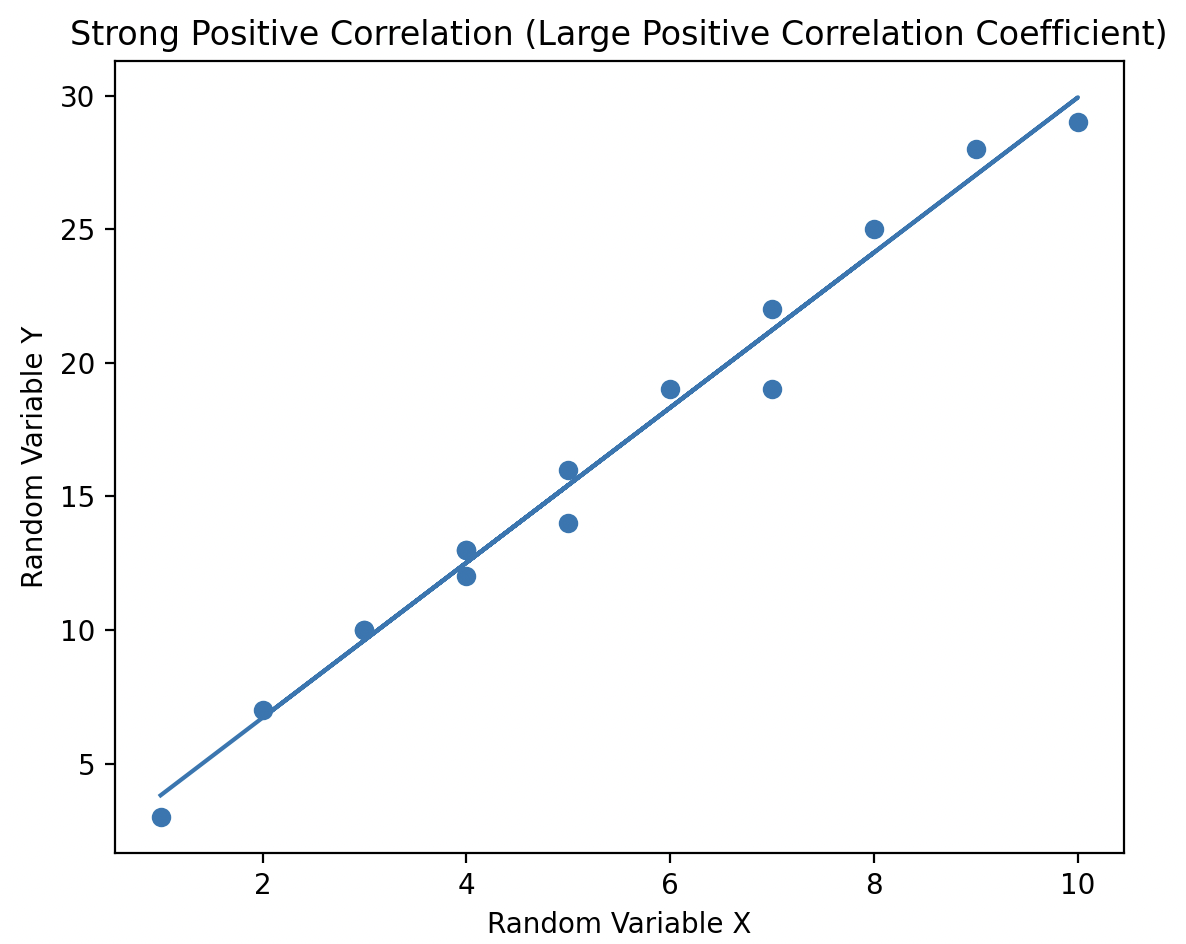
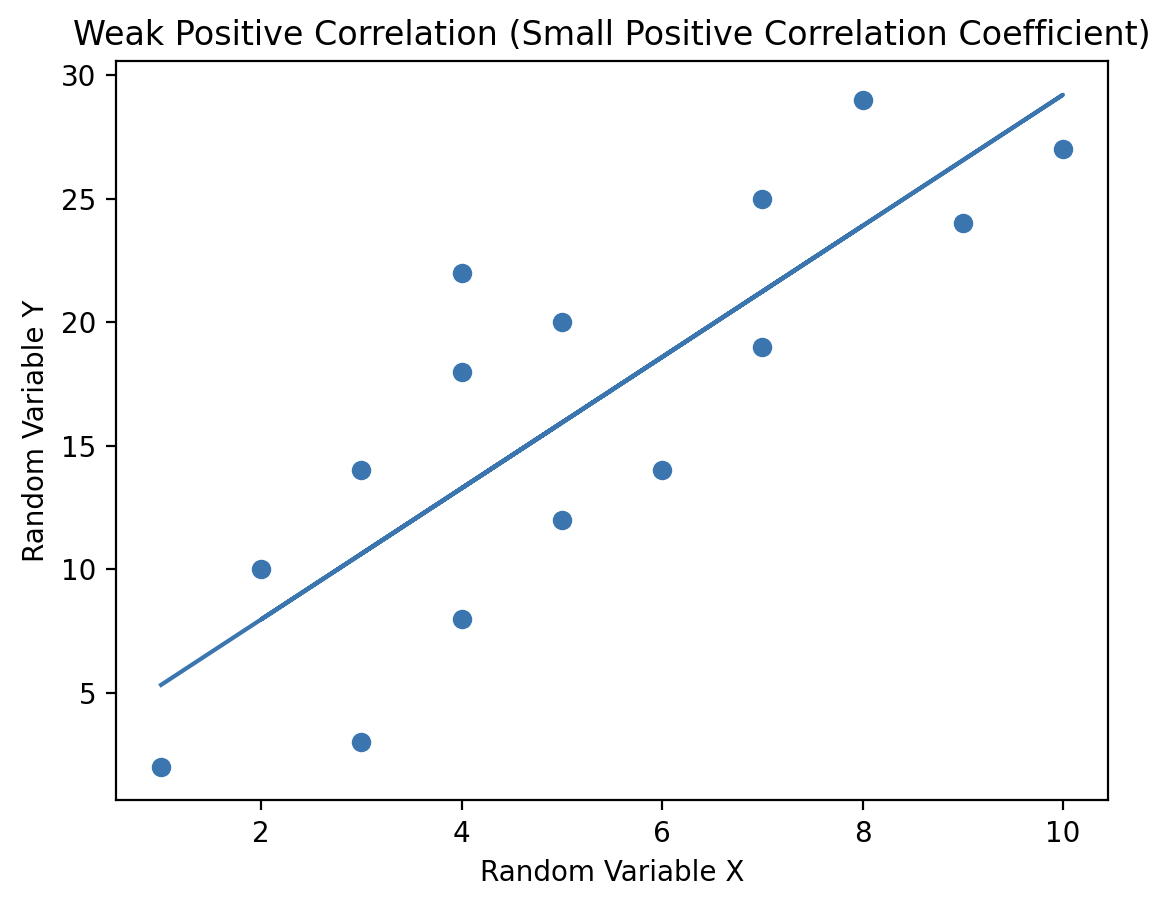
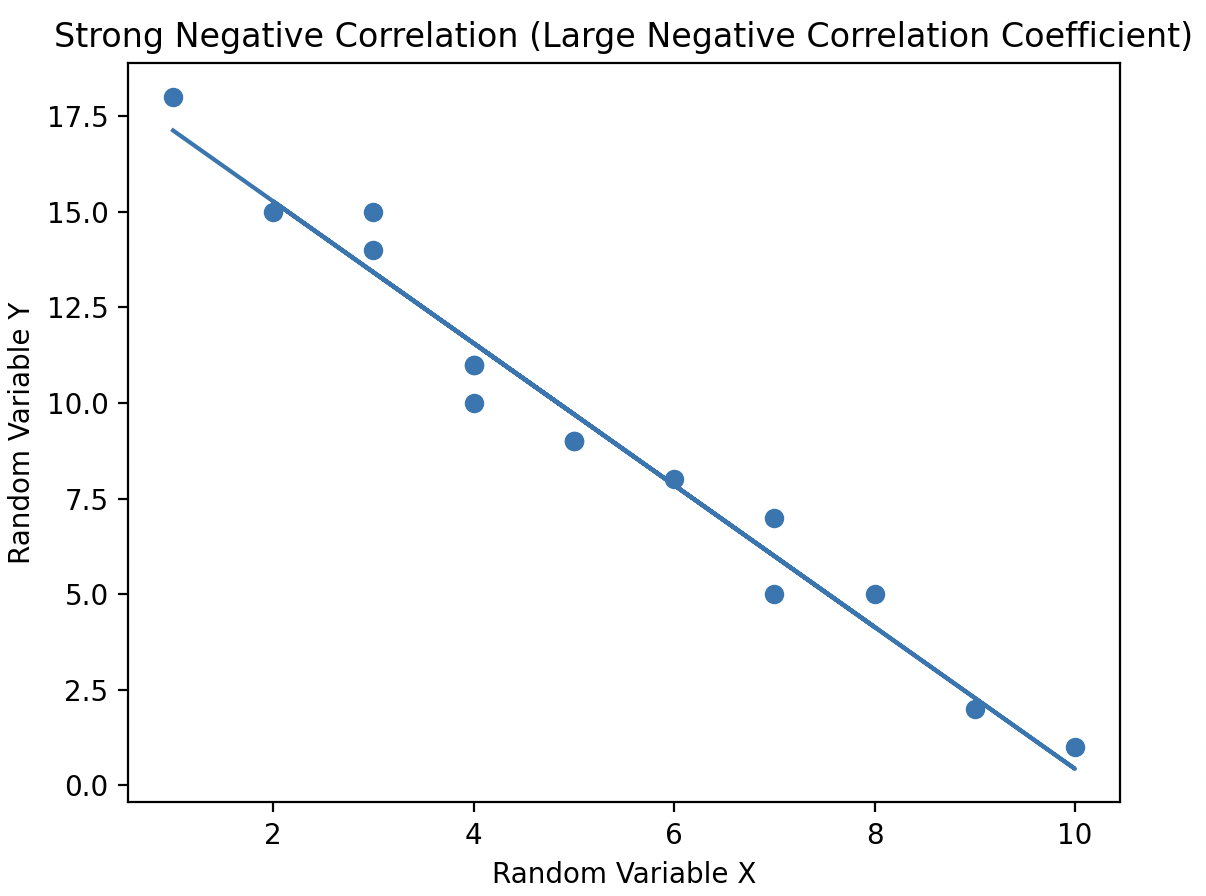
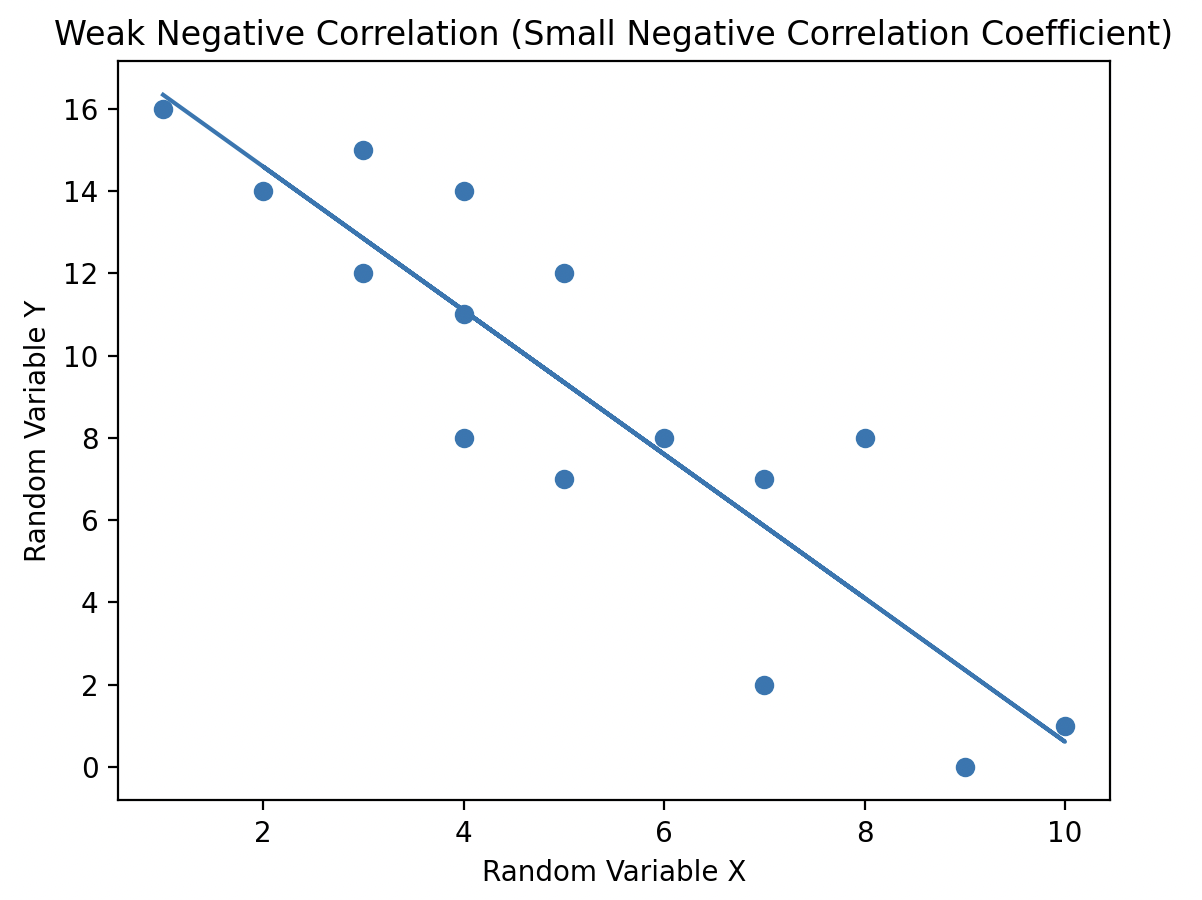
When a pair of random variables has a correlation coefficient value of 0, they are considered uncorrelated. In this case, there is no linear relationship between the variables, meaning no line can be drawn through the scatter plot to capture any trend or relationship between them.
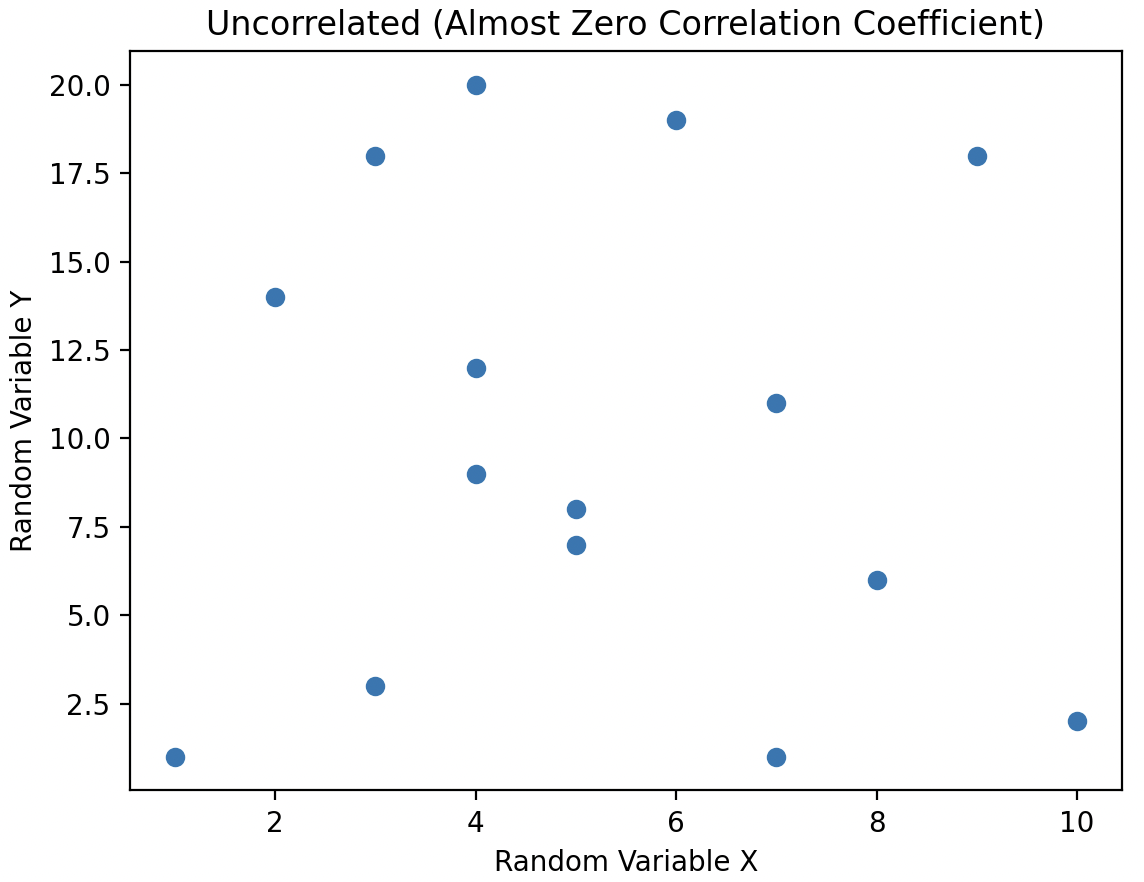
Uncorrelated random variables have no linear dependence between them, however, the two variables can be non linearly dependent.
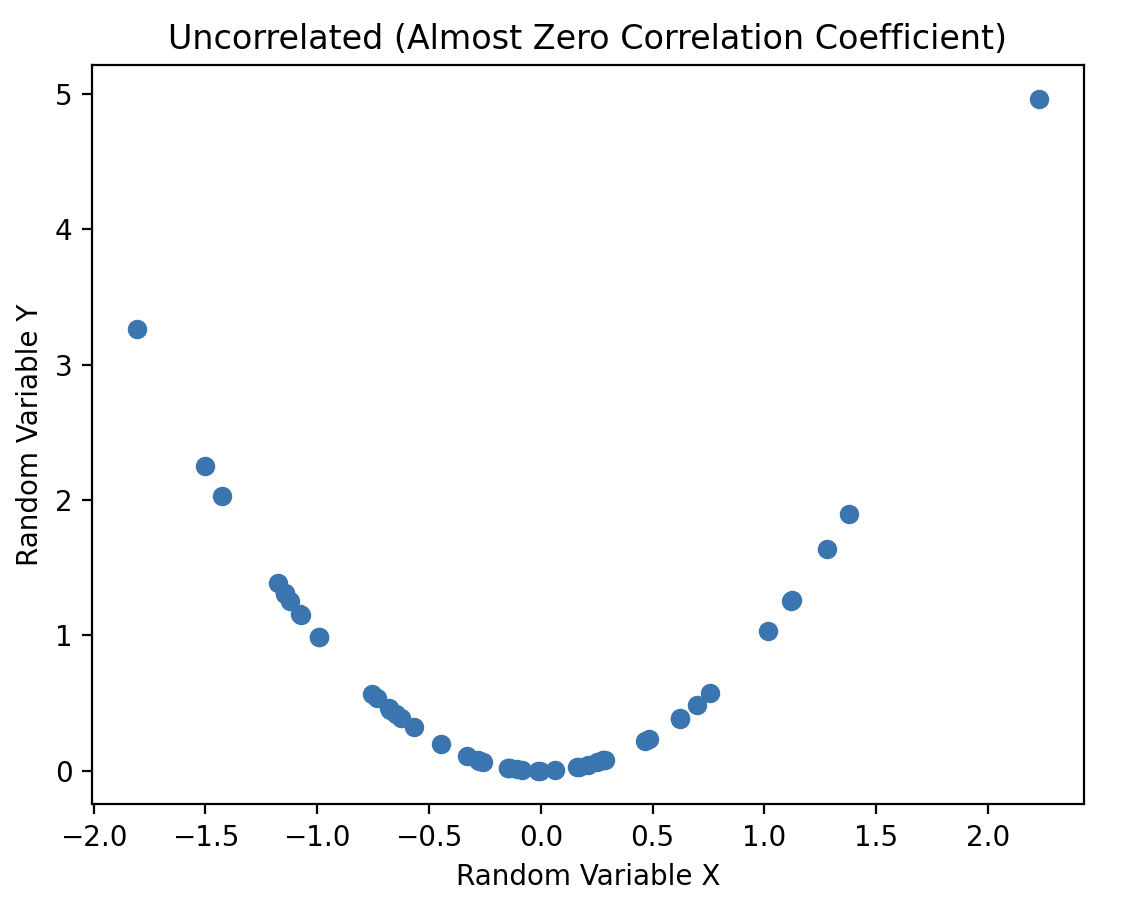
In the plot, the variables have a correlation coefficient close to zero, indicating they are uncorrelated. However, they are still dependent because knowing the value of variable X accurately predicts the value of variable Y through a simple non-linear relationship: squaring the X value to obtain Y.
Tip: When working with statistical data, always study data plots. It can be misleading to claim there is no statistical relationship when there is an obvious "smile" on the scatter plot!
When variables are dependent, knowing the value of one can predict the other:
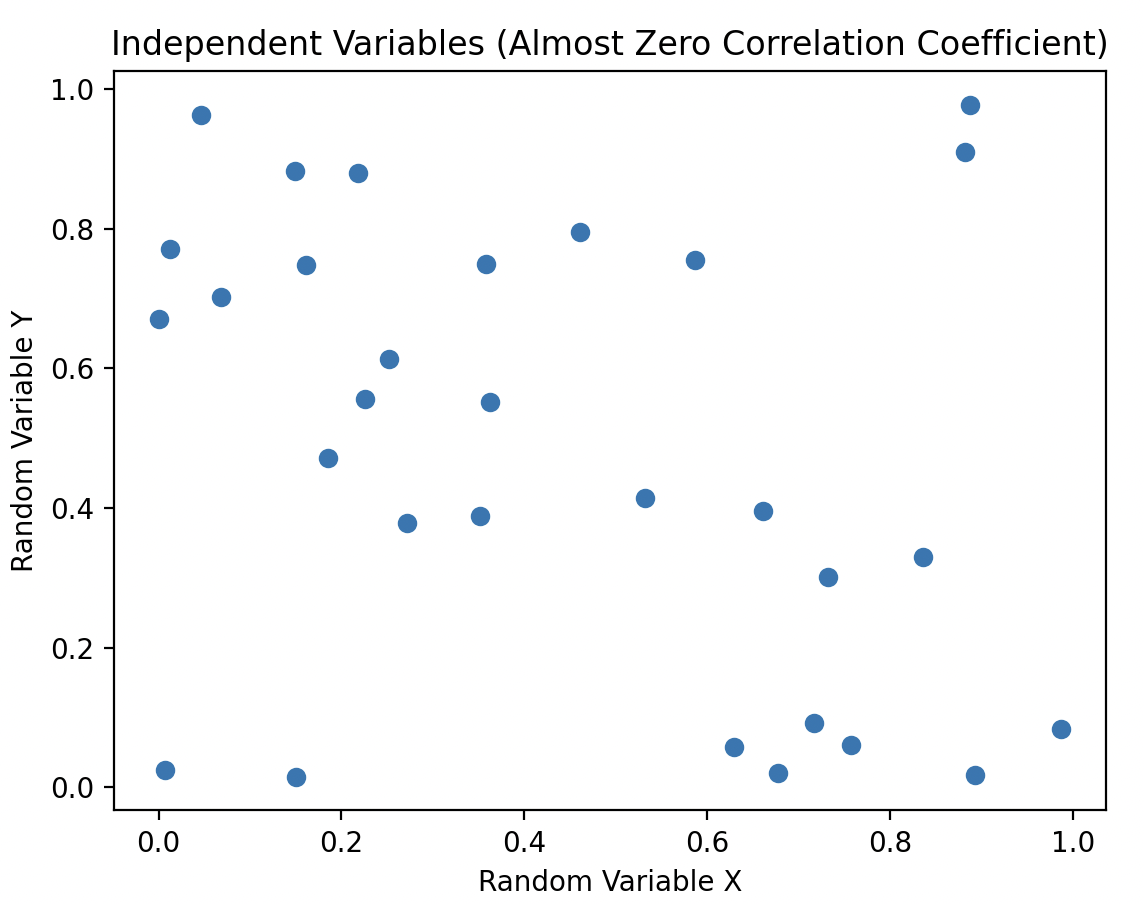
Independent variables have a correlation coefficient close to 0. All independent random variables are uncorrelated. However, it's not necessary for uncorrelated variables to be independent; they could still be non-linearly dependent.
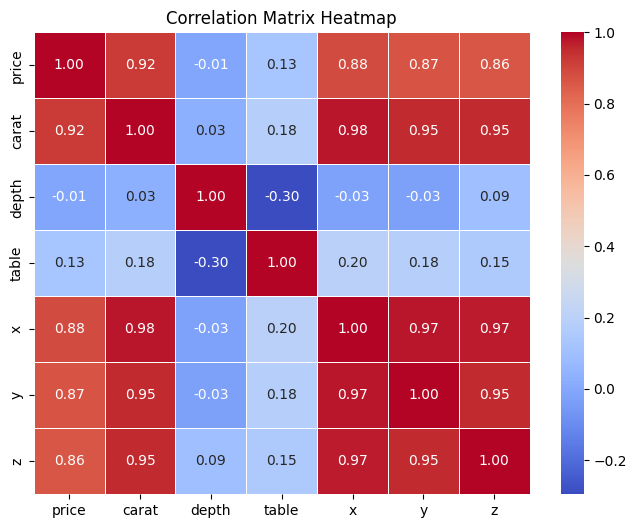
A correlation matrix is a table that displays the correlation coefficients between multiple variables in a dataset. Each row and column in the matrix represent a variable, and the cells contain the correlation coefficients between the corresponding pairs of variables. It's a useful tool in statistics and data analysis for understanding the relationships between variables.
Taking a closer look at the matrix, we can identify some patterns:
Data Science Discovery is an open-source data science resource created by The University of Illinois with support from The Discovery Partners Institute, the College of Liberal Arts and Sciences, and The Grainger College of Engineering. The aim is to support basic data science literacy to all through clear, understandable lessons, real-world examples, and support.